Kubeflow Components¶
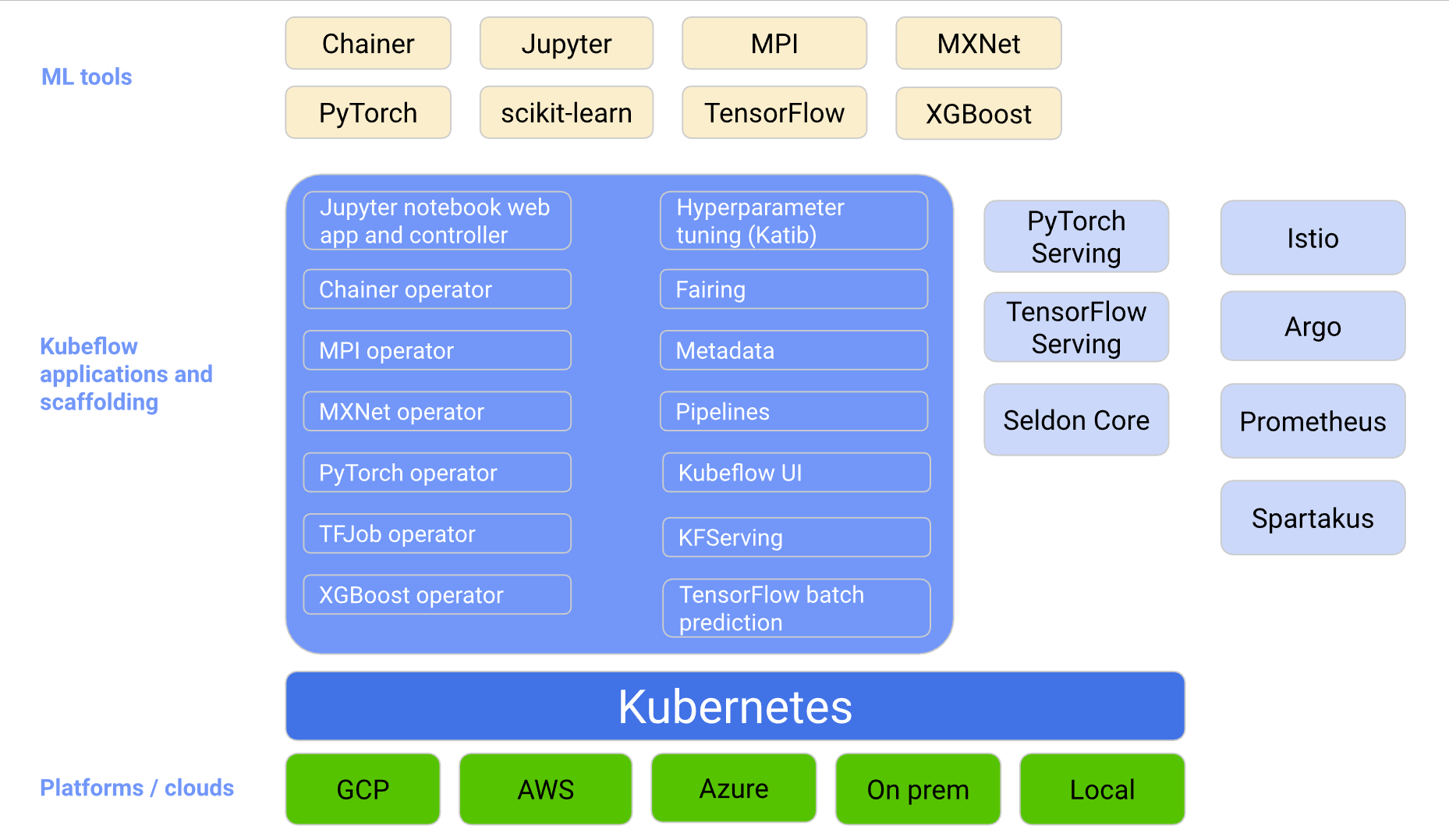
Kubeflow is a platform that provides a complete end-to-end machine learning (ML) solution. It includes components for each stage in the ML lifecycle, from data preparation to model training and deployment, all within a single, integrated platform. You can choose what is best for you, and there is no requirement to deploy every component. Kubeflow is an imperative tool for any organization looking to leverage the power of ML to accelerate innovation and drive business values.
Kubeflow streamlines data exploration, enabling you to easily discover and analyze relevant information. With Kubeflow, building and training ML models become more efficient, as the platform supports hyperparameter tuning and model versioning to optimize performance. Its advanced capabilities also include comprehensive analysis of model performance, ensuring that only the most accurate models are deployed. Additionally, Kubeflow manages compute power and serving infrastructure, allowing seamless integration with production environments. By offering a cohesive solution for all stages of ML development, Kubeflow revolutionizes the way you create, evaluate, and deploy models.
Jupyter Notebooks¶
Kubeflow deployments include services for creating and managing Jupyter Notebooks. You can customize your notebook deployment and your compute resources to suit your data science needs. With this service, you can easily create, edit, and share your notebooks with others, collaborate on projects, and save your work in the cloud.
Pipelines¶
Kubeflow Pipelines is a comprehensive solution for deploying and managing end-to-end ML workflows. A pipeline is a description of a ML workflow, including all the components in the workflow and how the components relate to each other in the form of a graph. A pipeline component is self-contained set of code that performs one step in the ML workflow (pipeline), such as data preprocessing, data transformation, model training, and so on. A component is analogous to a function, in that it has a name, parameters, return values, and a body.
When you run a pipeline, the system launches one or more Kubernetes Pods corresponding to the steps (components) in your pipeline. The Pods start Docker containers, and the containers in turn start your programs. You can schedule and compare runs, and examine detailed reports on each run.
Machine Learning Metadata DB (MLMD)¶
MLMD is the metadata management component of Kubeflow. Metadata is the data that includes information about the context of other data and is generated in each phase of the ML lifecycle. From the data extraction to the model monitoring phase, all ML related processes create specific metadata. MLMD is a centralized place for storing the metadata of the full ML lifecycle. It includes information such as the creator of different model versions, when they are created, the training data, parameters, and the place and performance metrics of each version of a model. It also provides information about the environment within which an ML model is built.
The Katib Hyperparameter Tuning System¶
Katib is a Kubernetes-native project for automated ML. It is a powerful hyperparameter tuning system designed to optimize ML model performance on Kubernetes. This highly scalable and flexible system supports various tuning algorithms, integrates seamlessly with popular ML frameworks, and provides a user-friendly dashboard for monitoring and visualization. By automating the search for optimal hyperparameters, Katib enables you to streamline your workflows and focus on more critical aspects of your projects.
Model Training Operators¶
Kubeflow’s model training operators play a vital role in simplifying and streamlining ML workflows. These operators are designed for popular frameworks like TensorFlow, PyTorch, MXNet, XGBoost and etc., allowing seamless integration and efficient resource management on Kubernetes. By leveraging these operators, you can effectively manage the training process, monitor progress, and scale your experiments. With Kubeflow’s operators, you gain the flexibility and power needed to tackle complex ML tasks while minimizing infrastructure complexities.
Central Dashboard¶
Central Dashboard serves as the hub for managing and navigating various components within the Kubeflow ecosystem. This user-friendly interface offers a comprehensive overview of your ML workflows, including experiment tracking, model training progress, and hyperparameter tuning results. The dashboard simplifies access to various tools and features, such as Jupyter notebooks, pipeline management, and resource allocation. By providing a unified view of your projects, the Central Dashboard enables you to monitor and manage your experiments efficiently, thereby accelerating the development and deployment of ML models.