MLOps with Kubeflow¶
The Kubeflow on vSphere distribution includes the core Kubeflow components and new components designed for the vSphere platform. Together with key Kubeflow add-on components and several other open source software, they form an enterprise ready machine learning operations (MLOps) platform. It is optimized for the VMware vSphere platform.
Google published a MLOps maturity model, which describes the level of automation in the key steps of MLOps including Data Extraction, Data Analysis, Data Preparation, Model Training, Model Evaluation, Model Validation, Model Serving and Model Monitoring.
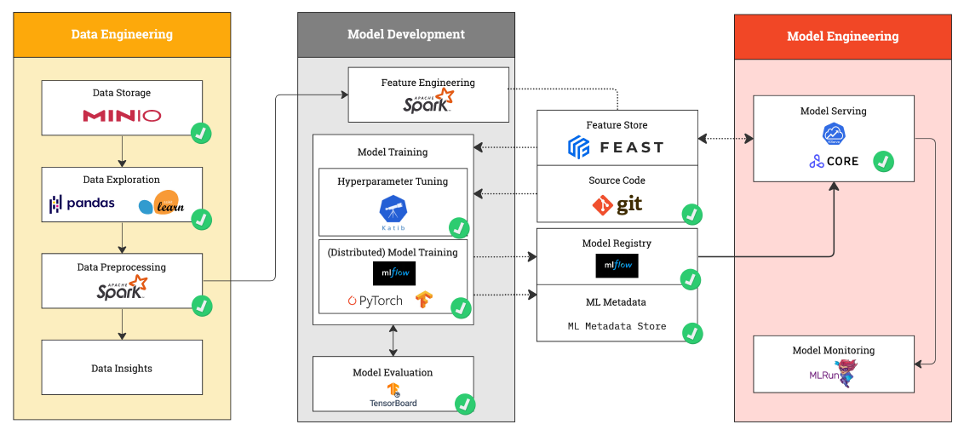
The Kubeflow on vSphere platform includes most of the key components for achieving the highest level of MLOps maturity, as illustrated in the figure below.
As described in the Google document, MLOps maturity level 0 indicates that the machine learning (ML) process for building and deploying ML models is entirely manual.
To achieve maturity level 1, the model training process should be automated to achieve continuous delivery (CD) of the model prediction service. A model training pipeline should be created and deployed for production purposes. Validated new data could be fed into this pipeline to generate a new model version automatically.
For maturity level 2, the model training process is automated with an ML pipeline and the pipeline generation and update process should also be automated to achieve complete continuous integration/continuous delivery (CI/CD) for the ML process. This MLOps setup includes the following components:
Source control
Test and build services
Deployment services
Model registry
Feature store
ML metadata store
ML pipeline orchestrator
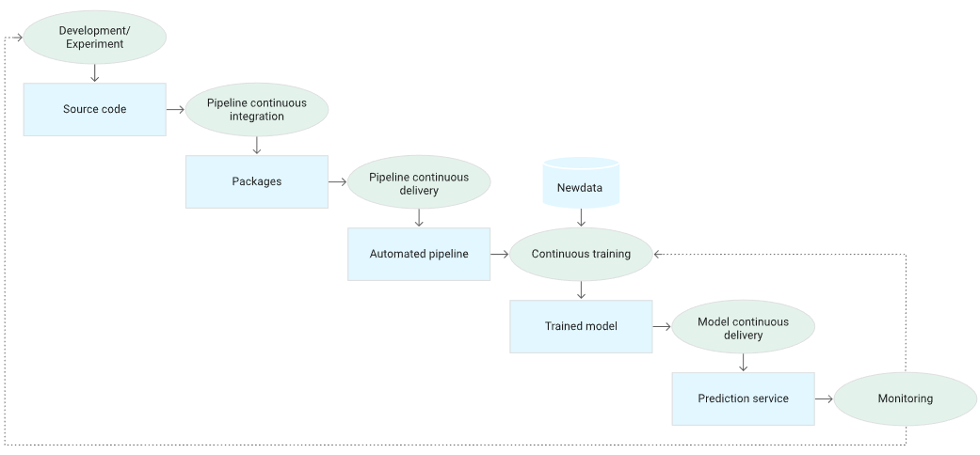
The following diagram shows the stages of the ML CI/CD automation pipeline:
The following Kubeflow add-on components or open source software are included or recommended in the Kubeflow on vSphere distribution to meet these requirements.
Feast is a Kubeflow add-on component that provides the feature store service. A feature store is a centralized repository where you standardize the definition, storage, and access of features for training and serving.
GitLab is an open source code repository and collaborative software development platform for large development and operations (DevOps) projects. It helps the engineering teams remove toolchain complexity and accelerate DevOps adoption.
MLFlow is a platform to streamline ML development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. It provides the model registry service for this platform.
Metadata about each run of the ML pipeline is recorded to help with data and artifacts lineage, reproducibility, and comparisons. It also helps you debug errors and anomalies. ML Metadata (MLMD) is a library for recording and retrieving metadata associated with your workflows. MLMD is an integral part of TensorFlow Extended (TFX) but is designed so that it can be used independently.
The data analysis step is still a manual process before the pipeline starts a new iteration of the experiment. The following software is included in the Kubeflow on vSphere platform for data storage and processing purposes.
Apache Spark is a distributed computation framework. It is used widely for data-intensive processing tasks. It is a multi-language engine for executing data engineering, data science, and ML on single-node machines or clusters. It supports multiple powerful features such as streaming data, SQL analytics, data science at scale and ML.
MinIO is an object storage solution that provides an Amazon Web Services S3 compatible API and supports all core S3 features.